BookHub
Pesquisar, Verificar e Converter Livros Sem Confiar em Nenhum Ficheiro
Leio num e-reader, e arranjar livros em EPUB normalmente acaba em sites onde metade dos botões são anúncios e cada download é uma lotaria. Fazer isso no meu PC principal, na mesma rede onde corre tudo o resto cá de casa, nunca me pareceu boa ideia.
Então, junto com o Claude, fiz o BookHub: uma PWA self-hosted que corre numa VM dedicada no homelab e trata cada ficheiro como hostil até prova em contrário.
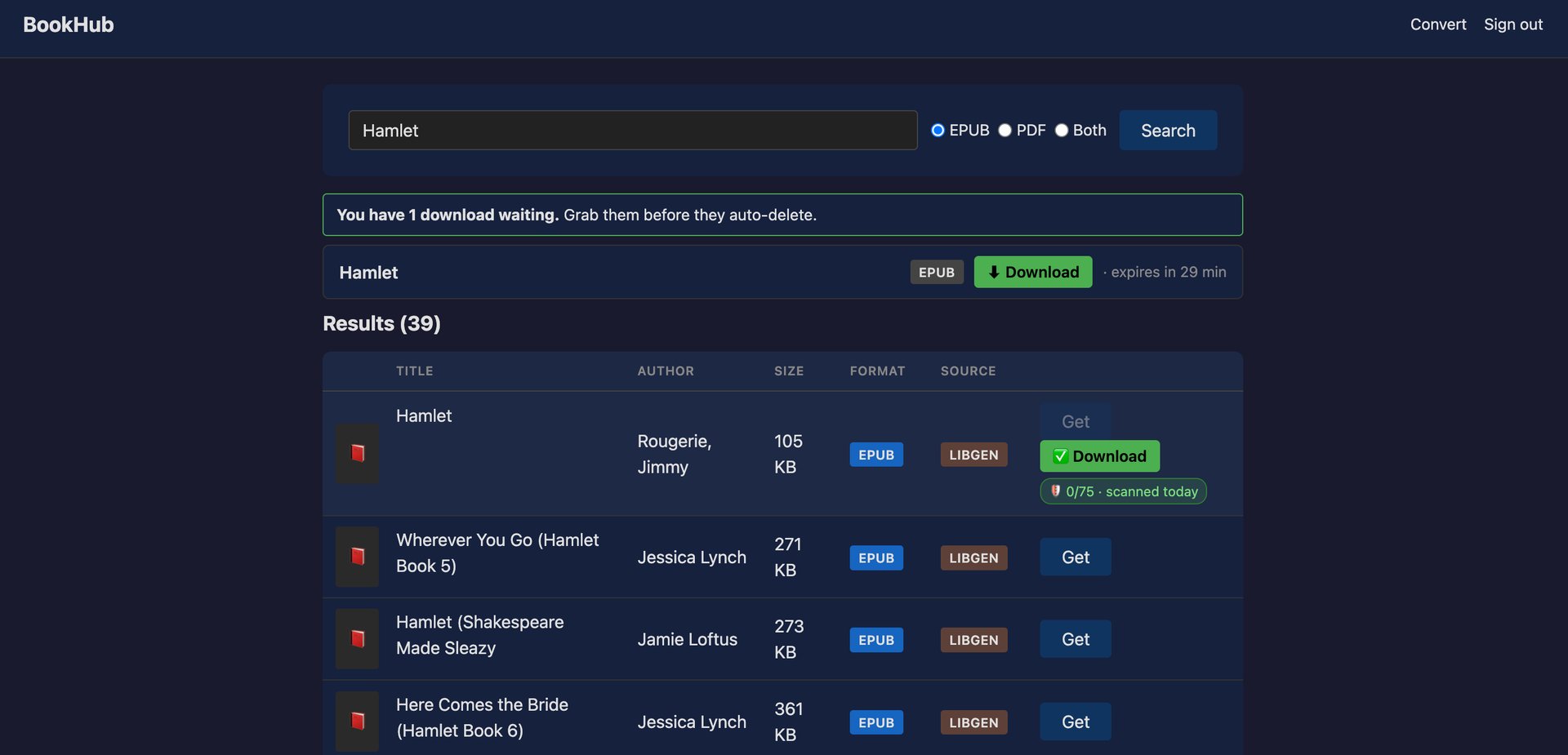
A pesquisa é a parte fácil. Procura no Anna's Archive, no Libgen e no Internet Archive ao mesmo tempo, filtra para EPUB/PDF, remove duplicados e mostra os resultados com capas, ordenados por tamanho, do mais pequeno para o maior. Havia também um provider do VK, mas o VK matou a API de que ele dependia, por isso ficou reformado.
O archive.org foi a boa surpresa: API pública limpa, sem Cloudflare no caminho e bastante stock de títulos em português. Quando um item tem vários ficheiros, a app escolhe o mais pequeno, por isso um EPUB de 1 MB ganha a um scan de 137 MB.
Quando escolho um resultado, o ficheiro nunca chega diretamente ao browser:
- o servidor faz o download para uma pasta de quarentena
- verifica o formato (proteção contra zip-bombs e polyglots, sem extrair nada)
- calcula o hash e envia ao VirusTotal
- só um veredicto "clean" recente é servido; ficheiros maliciosos, suspeitos ou impossíveis de verificar são apagados
Os ficheiros são temporários: um cleaner com TTL apaga tudo ao fim de 60 minutos.
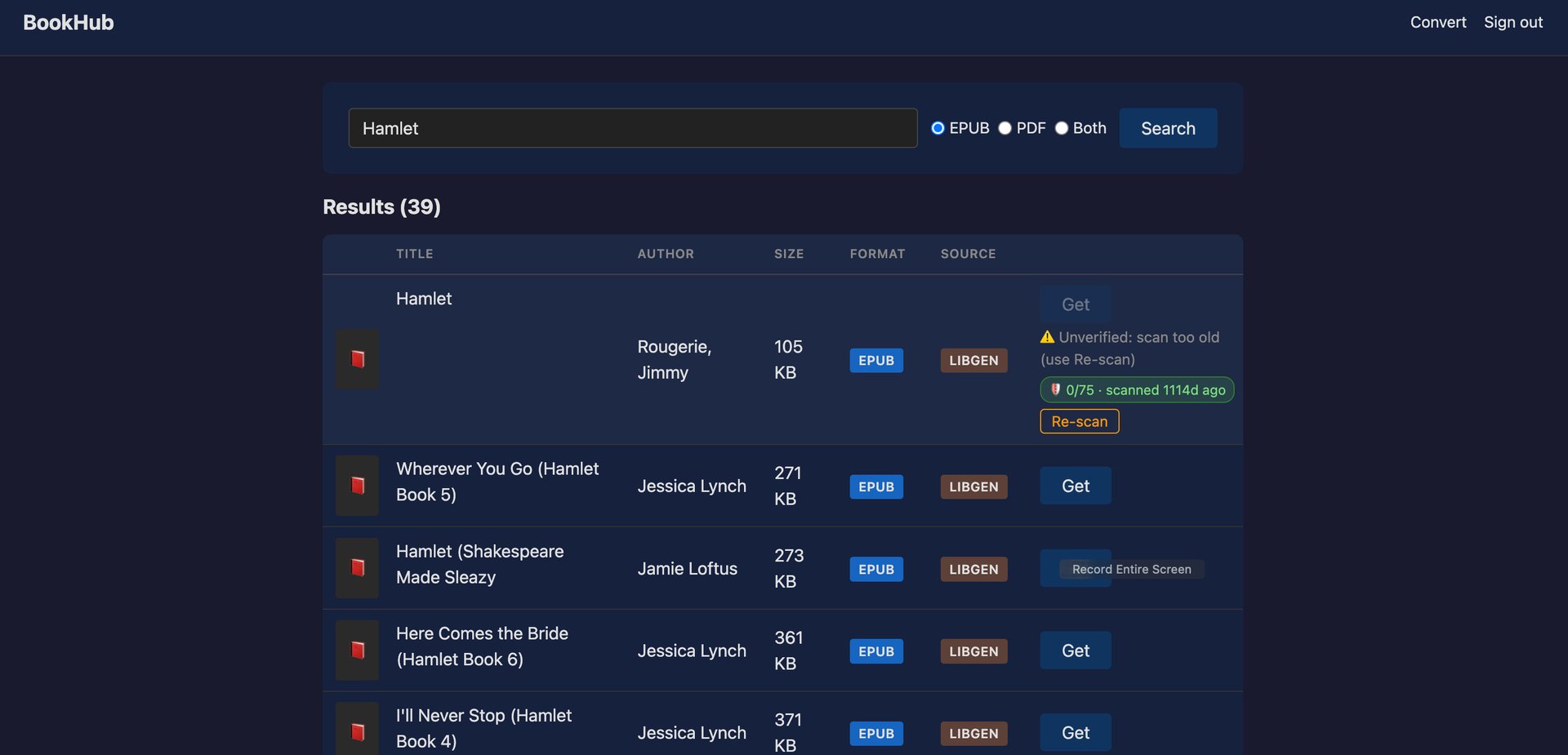
O uso real ensinou-me uma coisa aqui: livros antigos trazem veredictos do VirusTotal que são limpos mas antigos, e a app estava a apagá-los como não verificados. Agora um veredicto limpo vale até 5 anos, e há um botão de Re-scan para os restantes.
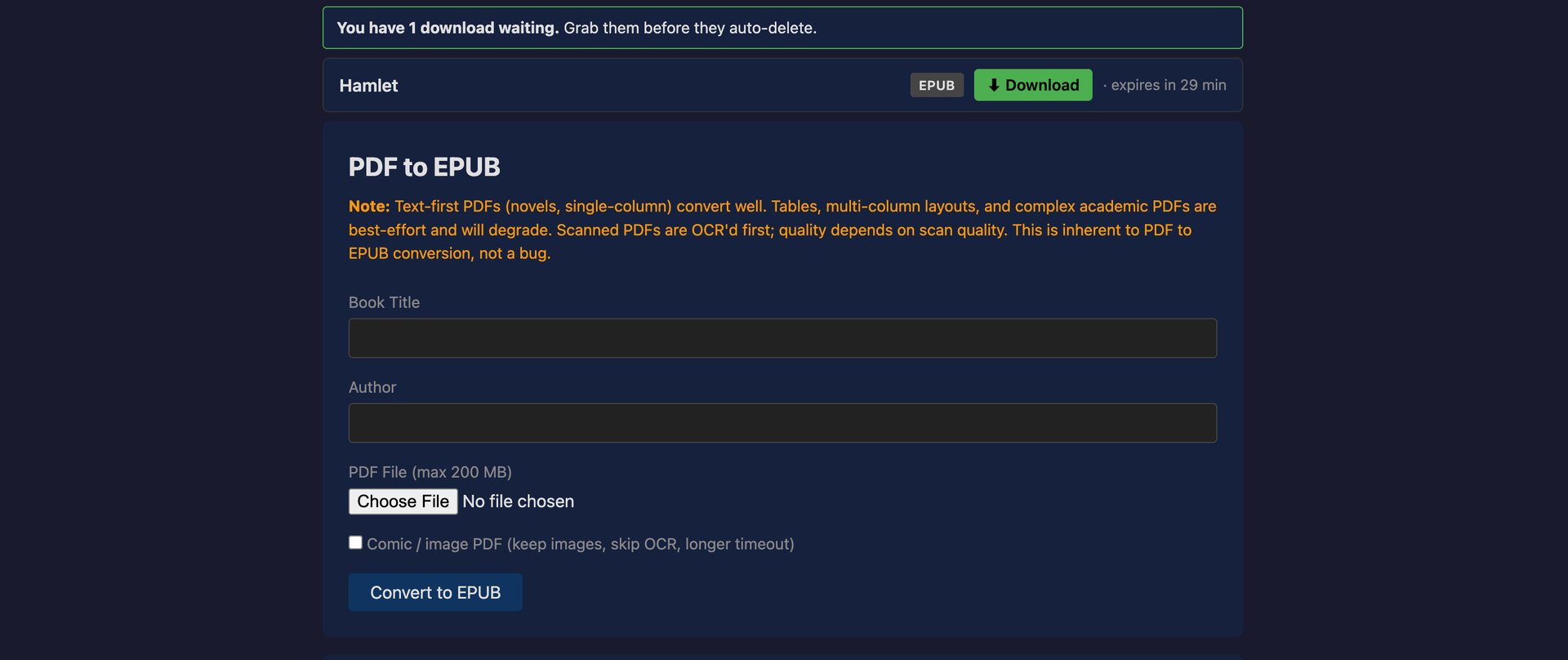
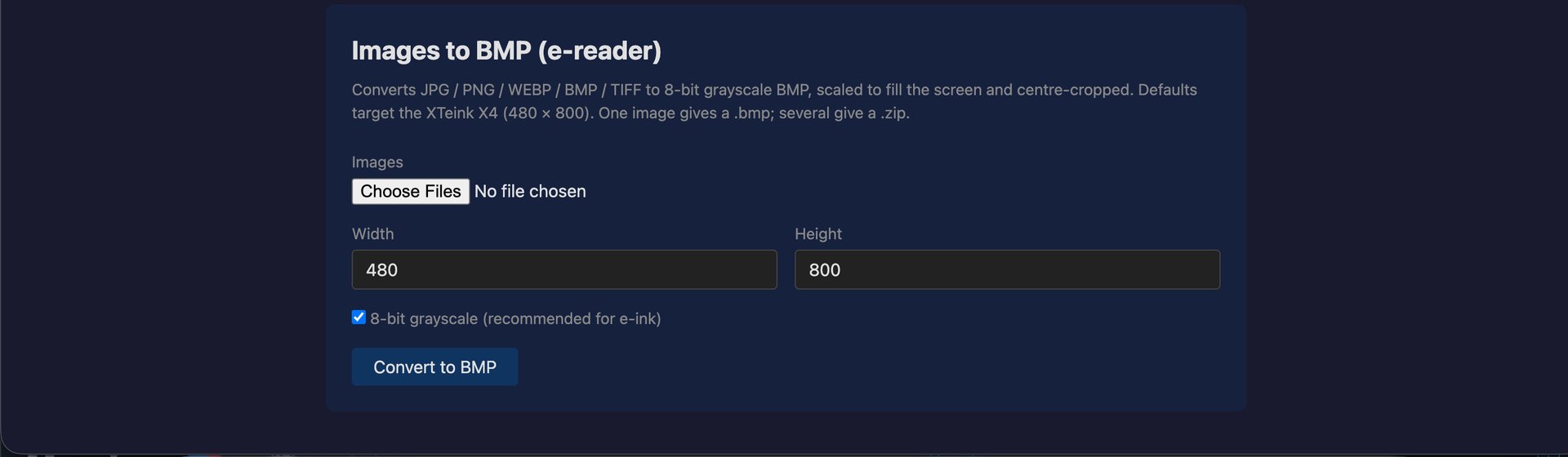
Há também um conversor de PDF para EPUB (Calibre + OCR), e é aqui que a paranoia começa a sério. Fazer parse de um PDF não confiável é a coisa mais perigosa que a app faz, por isso cada conversão corre num container gVisor (runsc) descartável: sem rede, read-only, só com a pasta daquele job montada, sem segredos no environment. O gVisor mete um kernel em user-space entre o container e o kernel real, por isso mesmo que um PDF malicioso explore o Calibre, cai numa sandbox sem nada para roubar e sem saída. A app também nunca toca no Docker socket diretamente para lançar estes workers; isso passa por um socket-proxy que só deixa criar e arrancar containers; tudo o resto é negado por defeito. A mesma página converte imagens para BMP grayscale de 8 bits, o formato que o meu e-reader quer para screensavers.
A app principal está containerizada com a mesma mentalidade: UID non-root, filesystem read-only, /tmp montado noexec, todas as capabilities de Linux removidas, no-new-privileges, limitada a 2 GB de RAM e 256 processos, e só escuta em loopback. Se algo escapar do código da app, não há muito para agarrar dentro do container.
A camada que mais gostei de construir foi a rede. A VM está numa VLAN própria e o OPNsense bloqueia todo o tráfego de saída para RFC1918: mesmo que isto seja todo comprometido, não consegue chegar ao Proxmox, ao NAS, nem a mais nada na LAN. O gVisor e a VLAN são paredes separadas: uma impede um parser de escapar para o kernel, a outra impede a app de se mover pela rede. São precisas as duas. O acesso de fora passa por um Cloudflare Tunnel com uma camada de identidade antes do próprio login da app, e a própria app passou por um audit de segurança depois do build: CSP e security headers, erros genéricos para o cliente, docs da API desligados em produção.
Stack: FastAPI, PWA em JS vanilla, SQLite. Sem framework, sem build step.
Tem limites: ficheiros acima de 32 MB não podem ser verificados no tier gratuito do VirusTotal, por isso não descarregam de todo (no caso do archive.org, a app pelo menos devolve o link público direto em vez de simplesmente falhar). O Calibre reformata texto bem, mas não reconstrói tabelas nem layouts de várias colunas. E os mirrors do Libgen morrem semana sim, semana não, por isso a app falha de forma suave e usa as fontes que estiverem vivas.
Uma última coisa: estas fontes distribuem material com direitos de autor, por isso isto fica privado, atrás do tunnel, para meia dúzia de utilizadores. A responsabilidade é de quem o corre.
O e-reader recebe EPUBs limpos e o meu PC principal nunca mais toca nesses sites.